



Please log in to comment
Hi everyone! Pokee AI is a company that focuses on building foundation agents via reinforcement learning, and we’re excited to introduce PokeeResearch-7B - a SOTA deep research agent open-sourced for the public!
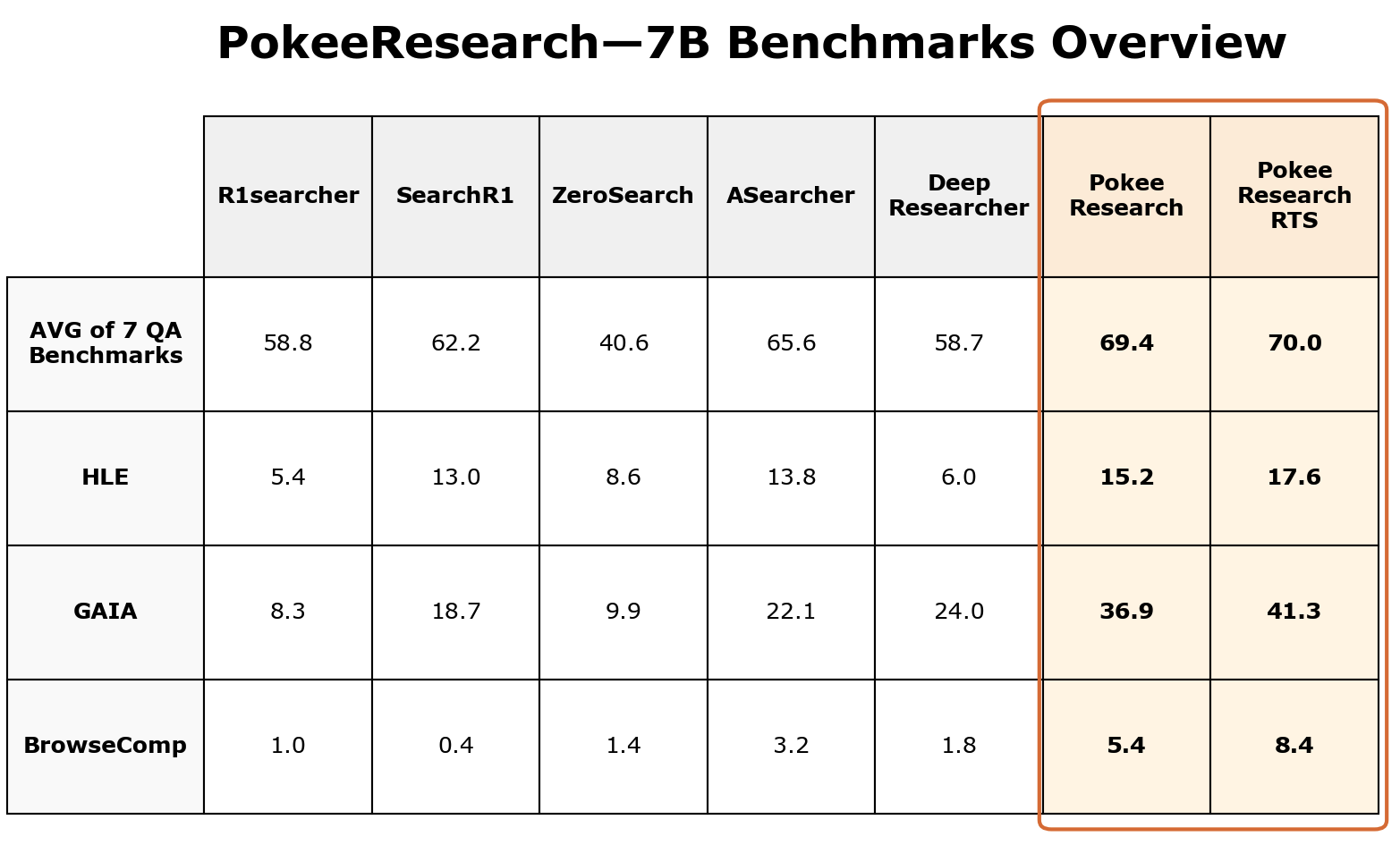
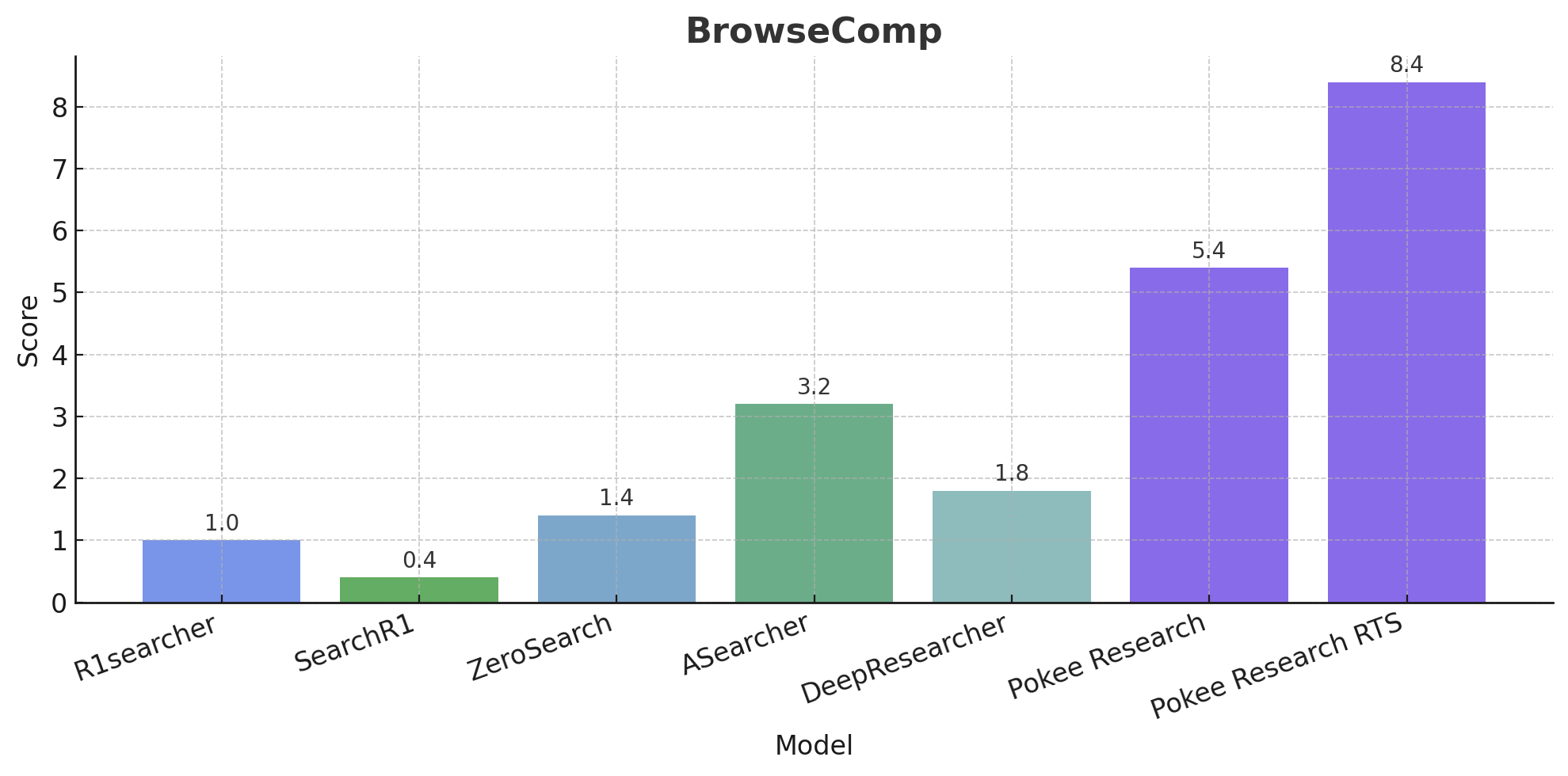
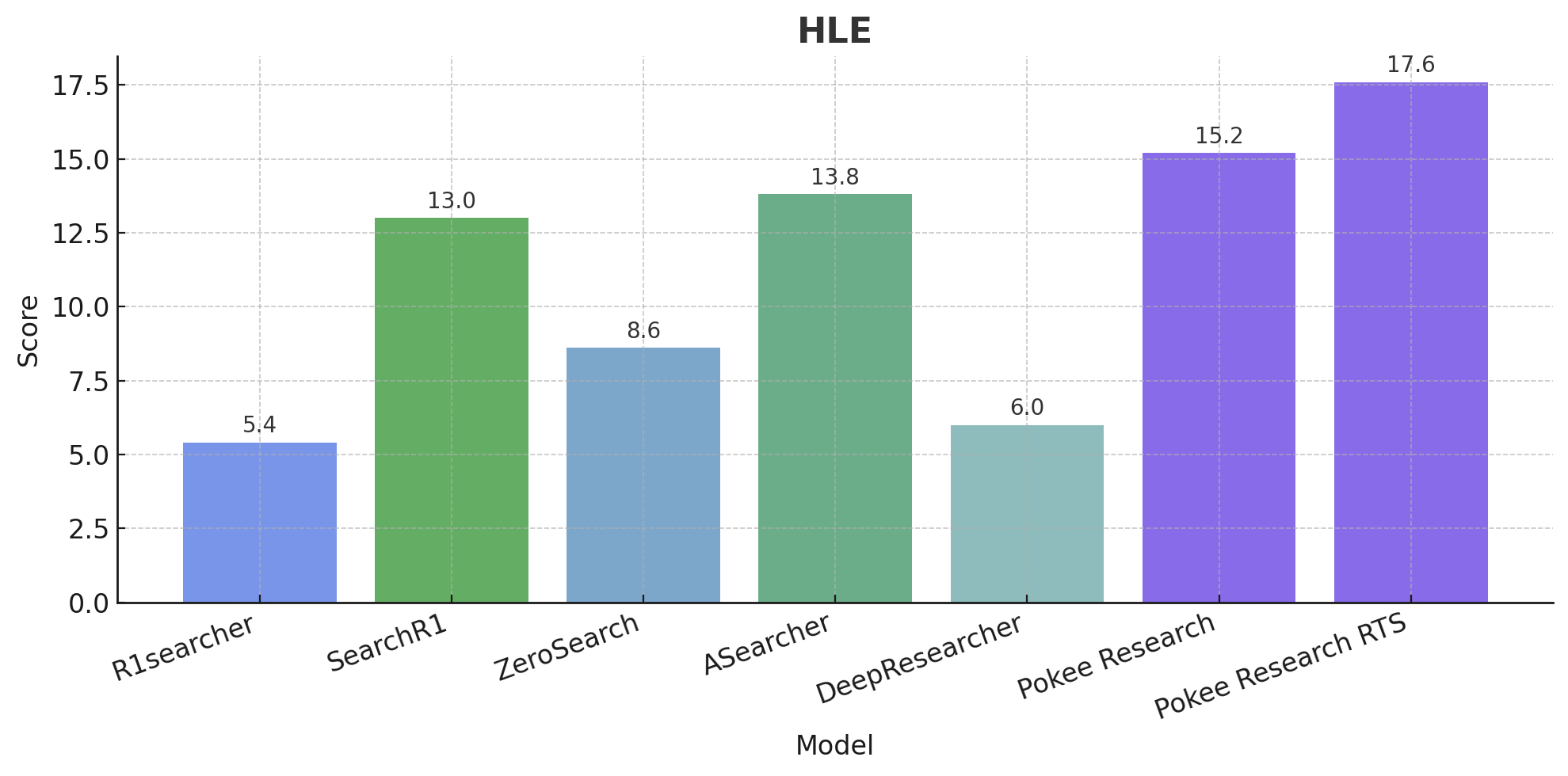
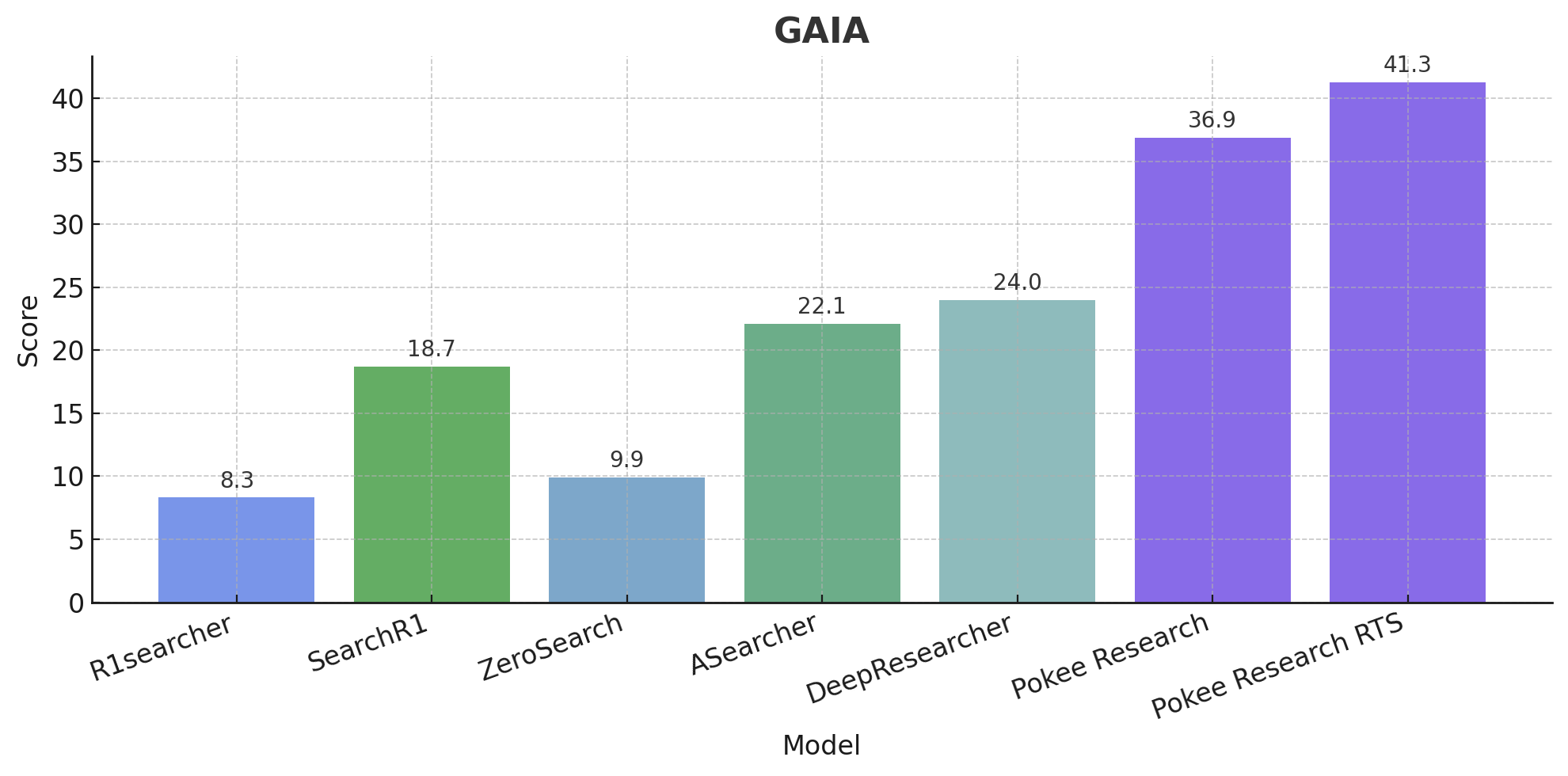
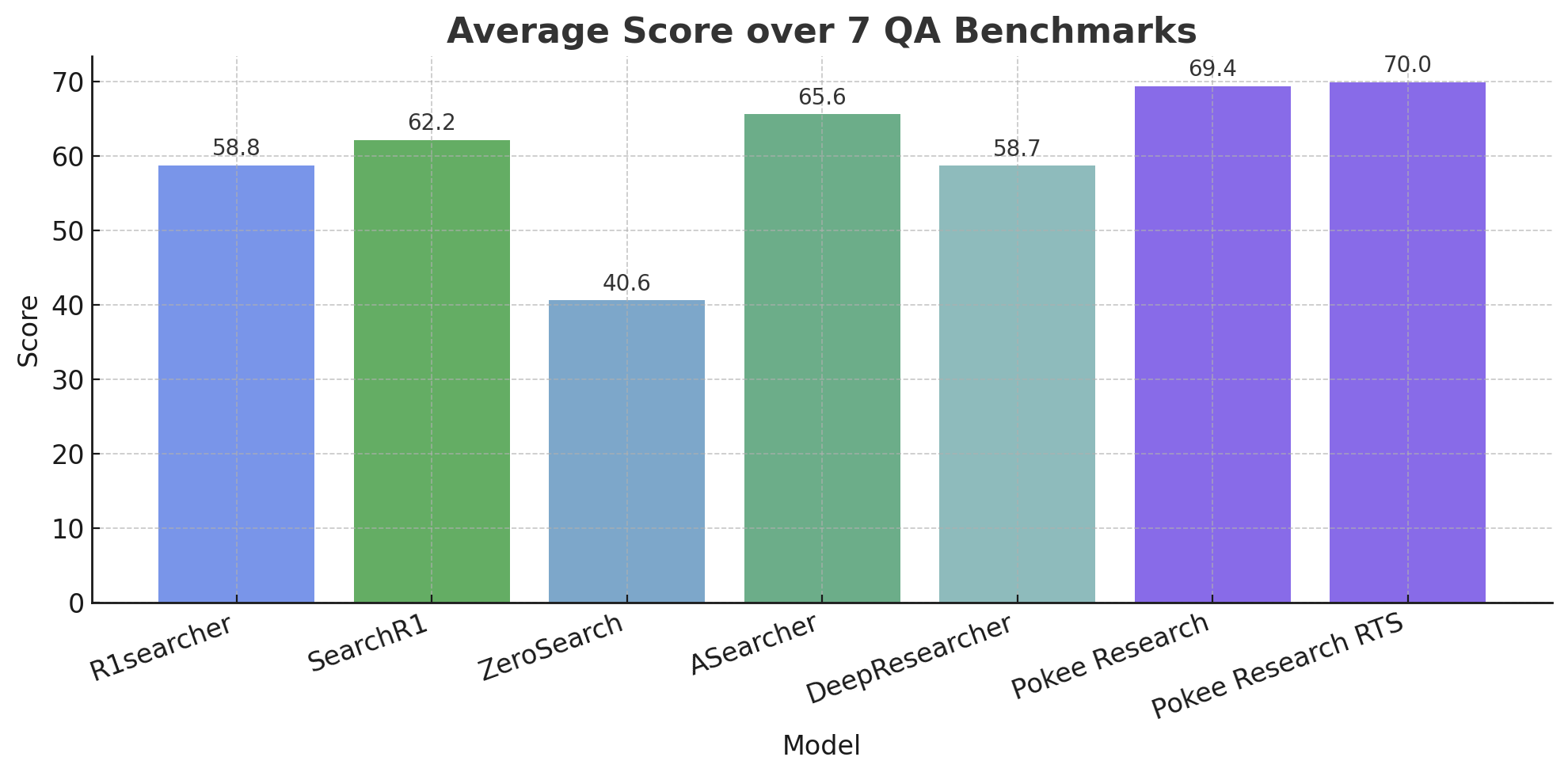
PokeeResearch-7B sets a new standard among deep research models its size across all key benchmarks. Critically it learns from AI feedback instead of just labelled data, allowing it to self-verify; hallucinate less; and do tool-calling at much larger scales.
For any research nerds among you 🤓 PokeeResearch-7B introduces:
- 🏗️ A 100% Reinforcement Learning from AI Feedback (with grounding) training pipeline trained for factuality, citation faithfulness, and instruction adherence.
- ⛓️A chain-of-thought, multi-call scaffold that launches multiple research threads and includes self-verification and error-recovery logic.
- 📖🔍Read the full paper here (https://arxiv.org/pdf/2510.15862) for all the gritty details!
Everything for 7B is open-source: model weights, code for inference, tool wrappers etc. We've gained a ton from the OS community & really wanted to give back. I'm excited to see what everyone builds!
In the meantime Pokee's got other stuff incoming - bigger, better models (see the big deep research model preview on our website!) & new products. So have fun w/ 7B & watch this space for the future! 🚀🚀🚀